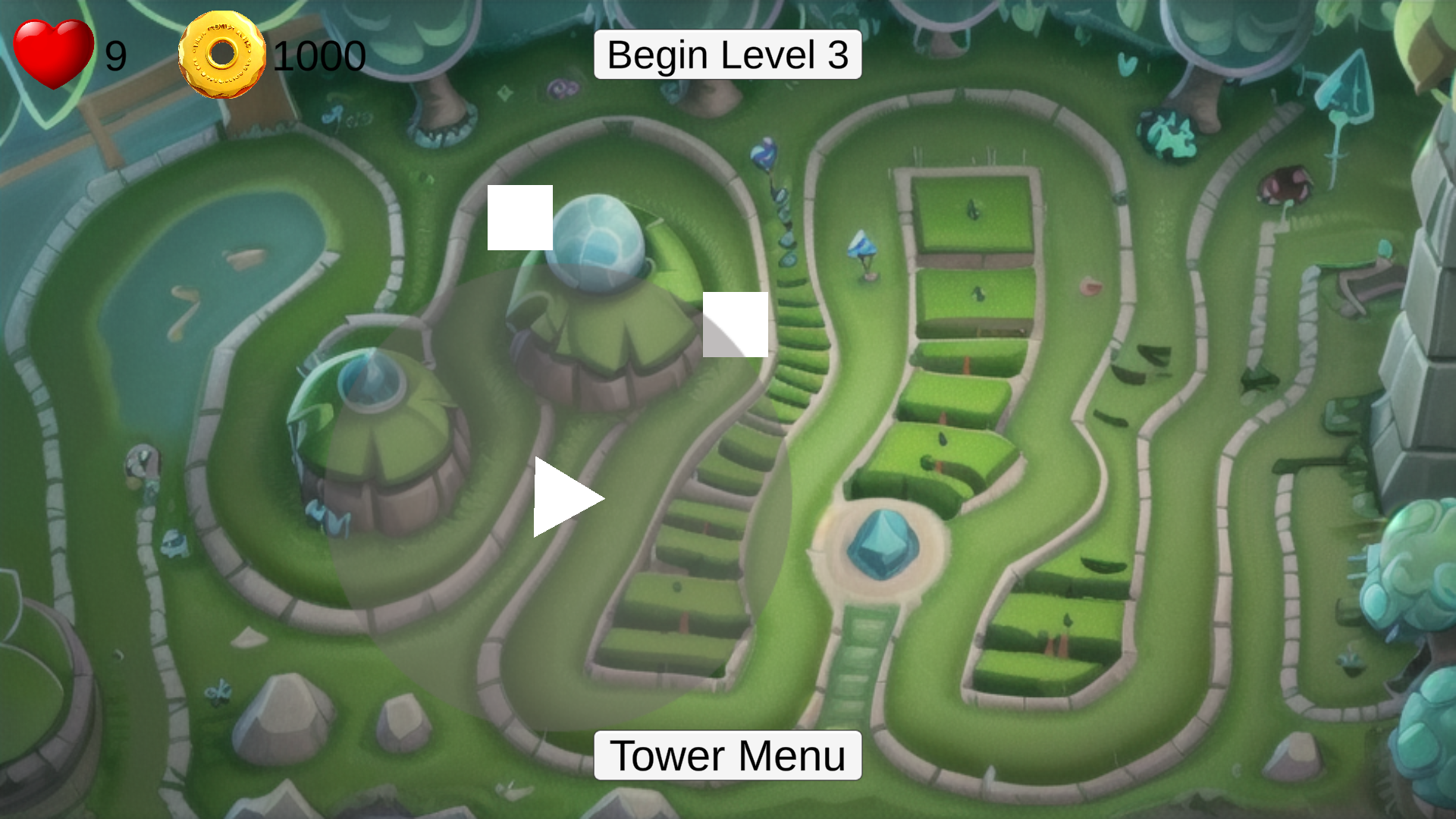
Crafting Game Maps with Stable Diffusion
Artificial Intelligence will revolutionize the world around us. But it will not only do so for consumers, creators will be affected just as much if not more. Generative AI is making things that would have required hours of the work of professionals before. In my newest dive into this world, I used Stable Diffusion to do the heavy lifting for the art in my Tower Defense game. Using stable Diffusions control net extension, I was able to turn this:

Into this:

Creating immersive and captivating maps for a tower defense game is a complex task that demands innovation and sophistication. In the realm of game development, there is a powerful yet relatively lesser-known tool at our disposal - Stable Diffusion. This cutting-edge technology not only empowers game designers to craft intricate and dynamic landscapes but also introduces an unprecedented level of stability and coherence to the map generation process. In this blog post, we will delve into the fascinating world of using Stable Diffusion for map design in tower defense games, exploring its limitless potential, and offering insights into how it can elevate the gaming experience to new heights. Whether you’re a seasoned game developer seeking to revamp your projects or a budding enthusiast with a passion for creating engaging game environments, this exploration of Stable Diffusion’s role in tower defense map design is bound to inspire and inform your creative journey.
To get started you need Stable Diffusion, I used Albert Bozeman’s video on the subject to get started. He also has one on how to set up control net.
After getting all of this set up, I decided to check out my general idea. Which was to create a basic outline for which Stable Diffusion could fill in the gaps. To give some background info, there are three control-net models that I used, Scribble, Depth and Canny, with Canny being the base model that is most associated with control-net. All have the same basic idea. You input a base image and a prompt to describe what you want to happen to that image and the control-net generates something for you.
First I tried doing scribble mode which was suggested on some message boards and articles as a better alternative to Canny as it allowed for more fuzziness around the edges, literally and figuratively, giving the AI more leeway as well as providing a less rigid image from which to work with. However, the result was not always perfect. I definitely had to play with the prompt a bit, different types of prompts(industrial, desert, castle) had different needs, so I had to customize the prompts a bit adding different levels of ‘top down view’ or whatever that specific prompt needed. However, what I found was that using different models of control-net could yield various results that the user was looking for. So using scribble gave you more of a fluid image, while canny gave you a very rigid non-unique look, finally depth worked better sometimes than others, but definitely gave interesting backgrounds with obviously more depth.
Image I got using Scribble:

Image I got using Canny:

Image I got using Depth:

I found that I had no favorite model as other bloggers mentioned, for me scribble, depth and canny all provided good results at different points and could be used to attain similar yet distinct backgrounds. Although scribble was by far the least dependable, having small defects and a lack of straight paths. After doing some exploring I managed to find the image that control-net uses as a base and that told me everything I needed to know about why scribble was so inaccurate:
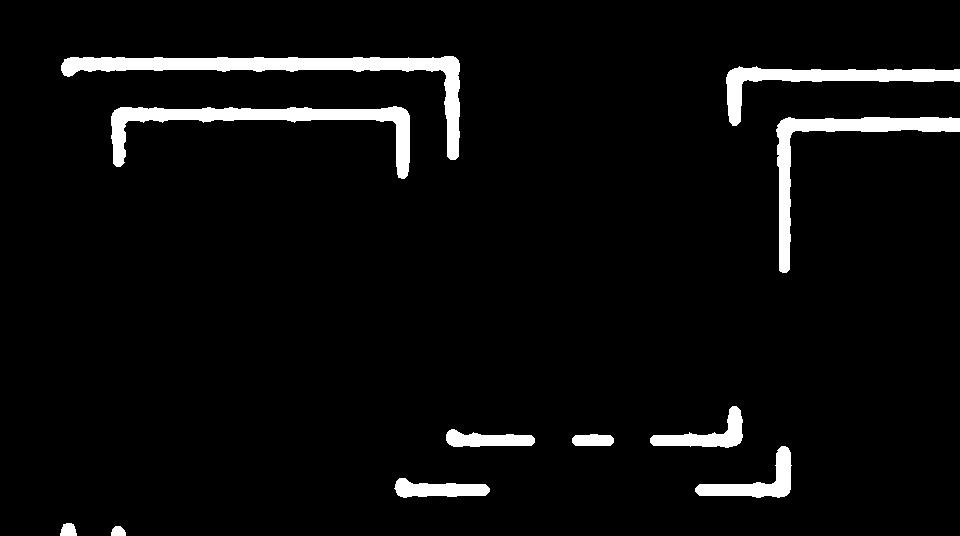
However, after some experimenting I realized that the power of the scribble was that it was designed to create images from meandering lines such as the one shown below:

Which gave me this result, which I thought was pretty cool and I ended up using it in the game itself: